그냥 Model을 바로 학습 해보면 안될까?
이전 글 : Value function 추정
[Artificial Intelligence/Reinforcement Learning] - 추정 - Value Function Approximation
추정 - Value Function Approximation
모든 Value function 을 반드시 다 계산 해야 할까? 추정 할 수 있는 방법을 알아보자 이전 글 : 모델프리 off-policy Control [Artificial Intelligence/Reinforcement Learning] - 모델프리 학습 - Model Free L..
skidrow6122.tistory.com
Model을 학습 한다는 것
이번 포스팅에서는 모델을 바로 학습 하는 법 즉, Model based MDP에서 학습(learning)과 Planning을 결합하는 법에 대해서 다뤄 보고자 한다. 이전에 다루었던 Model based MDP와 Model Free MDP의 차이에 대해 아주 간략히 키워드만 뽑자면,
- Model based RL
- 모델을 알고 있으니 experience를 통해 model을 학습한다.
- 모델을 통해 value function 또는 policy를 구하는 행위를 Planning 이라 하고 DP 기법을 사용한다.
- Model Free RL
- 모델이 없다.
- 따라서 MC, TD와 같은 샘플링을 통한 experience를 통해 value funtion 또는 policy를 학습한다.
사실 대부분의 현실 문제는 Model based 라고 할 수 없고 Model Free 상황에서 출발 한다고 보면 된다. 하지만 지금껏 다루어 왔듯이 Model Free 는 학습하는 방식이 매우 까다롭고 복잡한 것을 알 수 있었다.
Model Free 상황에서 어떻게 했는가? value approximation 을 통해 value function 자체를 학습 했고, Policy Gradient를 통해 경험으로 부터 얻은 데이터를 가지고 Policy를 다이렉트로 학습 했었다.
그런데, 만약 이러한 단계 없이 똑같은 experience 를 통해 model 자체를 학습하여 Model 을 얻는 다면 Model Free 문제는 이제 Model based 문제로 바뀔 것이다. 이것을 기반으로 Planning을 해보면 훨씬 간단하지 않을까? 이 과정이 곧 본 포스팅에서 다루려고 하는 learning 과 planning 을 single architecture 를 통해 통합 하는 기법이 된다.
지금까지 알고 있던 model based RL의 메커니즘은 아래와 같다.

즉, 초기값 value/policy 에서 출발하여 실제 action을 수행하고 model 을 학습한후 model이라는 문제를 단순화 시킨다.(model approximation) 이후 단순화 된 모델 기반으로 planning을 수행하고, 마지막으로 각 state들의 value를 모두 업데이트 하는 과정을 반복하는 것이다.
Model 을 학습한다는 의미가 뭘까?
이 질문에 앞서, Model 이란 뭘까?
Model 은 environment가 실제로 수행하는 일을 뜻한다. Model $M$은 MDP $<S,A,P,R,\gamma>$ 와 파라미터 $\eta$ 를 뜻한다.
$S,A,\gamma$ 는 익히 알다시피 state 와 action, 그리고 discounted factor이므로 확정적인 값이고 결국 모델을 구성하는 environmenet는 state transition probaility $P$ 와 reward $R$ 이라고 함축할 수 있고,
$\eta$ 는 model을 학습 하기 위한 파라미터 로서 $P,R$ 의 확률을 해당 파라미터를 통해 approximation 하는 용도라고 보면 된다.
Model Free MDP는 지금껏 prediction 과 control 두가지 큰 시퀀스를 거쳐왔는데 결국 $P,R$을 모르니 실제로 에피소드를 진행하면서 에피소드 안에서 어떤 state 에서 어떤 action 을 했더니 확률적으로 다음 state’ 결정이 어떻게 되더라...라고 얻은 인사이트를 가지고 추정 해왔던 것이다.
이러한 Model Free MDP와의 차이점에서 보면, 결국 Model based MDP로 만든 $M$은 $M = <P_{\eta},R_{\eta}>$ 와 같이 파라미터 $\eta$로 prbability 와 Reward 를 추정한 결과라 할 수 있다.
$$ S_{t+1} \approx P_{\eta}(S_{t+1} | S_t, A_t) $$
$$ R_{t+1} \approx R_{\eta}(R_{t+1} | S_t, A_t) $$
즉, approximation 한 probability 와 reward function 을 통해 state 전이 및 return 을 받는 다고 보면 된다.
이 전제를 위해 P와 R은 서로 독립이라 가정한다. 각각을 따로 따로 구할 수 있어야 하기 때문이다.
그럼 이제 Model 을 Learning 한다는 관점으로 확장해보자.
목적은 experience $<S_1, A_1, R_2, ... , S_t>$를 통해 Model $M_\eta$를 추정하는 것이다.
결국 $M_\eta$를 추정 하겠다는 문제는 $P_\eta , R_\eta$ 과 실제 $P,R$ 값이 얼마나 차이 나는지에 대한 에러값을 줄여나가는 문제로 해석 할 수 있다.
즉, 우리가 구하고자 하는 값들의 아웃풋에 대한 실제 값을 true label이라고 디자인 한다면, 문제 자체가 우리가 익히 알고 있는 supervised learning 형태가 된다. 경험에서 나온 결과를 그대로 리턴하는 function을 만드는 것이 곧 목표이기 때문이다.
$R$ 자체는 스칼라 값일 것이므로 이것이 그냥 true label 이 되는 것이고 이를 loss function 화 하여 MSE로 정의할 수 있다. 이 reward function 은 모든 s,a set들에 대해서 적절한 reward 를 받은 사실을 true label로 가진다면, 곧, 다른 s,a pair 를 입력으로 넣었을때 받았던 true label을 그대로 리턴 하는 모델을 만들었다면 이것이 곧 reward function 을 알맞게 학습 했다라고 하는 지도학습 문제인 것이다.
$P$ 는 확률 분포 형태이므로 KL divergence 라는 기법을 쓴다. 이는 두 확률 분포의 차이를 계산 하는 기법으로 이것 자체가 loss 가 된다. 즉, 모델에서 무수히 많은 경험을 통해 S에서 A를 선택했을때, 다음 state 가 무엇이 되더라는 것을 확률 적으로 알 수 있고, 이 과정을 무지 많이 하다보면 결국 P도 실제 P와 근사하게 될 것이라는 믿음에서 출발한다. 결국 P역시 estimation 의 문제이고 확률 분포의 추정이니 이것은 곧 density estimation 의 문제가 된다.
또한 파라미터 $\eta$ 는 전체 loss를 줄이는 방향으로 minimize 해야 하는 대상 값이되고 Neural Network 로 학습 한다.

종합 하면, model 을 학습 한다는 것은 곧 output value를 최대한 근접/근사 할 수 있는 function을 만드는 regression 문제라고 할 수 있다.
Model based learning 의 장단점
Model based RL은 일단 supervised method 를 사용하니 단순하고 효율적이고, 모델의 불확실성이 있을때도 학습과정을 거치니 문제를 해결 가능 하다는 장점을 가지고 있다.
반면에, 학습 해야 할 파라미터가 하나 더 늘어나기 때문에 에러가 발생 할 수 있는 원천이 하나 더 늘어나는 셈이니 모델 자체를 잘 설계 해야한다는 제약 사항 또한 존재 한다.
Model learning 과 Planning 과정
model을 learning 하는 과정과 planning 하는 과정을 알아보고 이들을 결합하는 방법론에 대해 접근해보자.
Model learning
모델 학습 방식으로 단순한 table lookup model을 예로 들어 볼 수 있다.
Model 은 MDP와 Probability, Reward 로 이루어 져있고, 우리는 이 Probability 와 Reward를 모르는 상태이다.
table look up 은 단순히 agent 의 state 로의 방문 횟수를 카운트 하여 Model을 추정하는 방식이다. 즉, $N(s,a)$ 를 세는 것이고 $s와 a$는 experience action pair 가 된다.

- $\hat P^a_{s,s'}$ 는 각각의 state 가 어떻게 이동하는지를 모두 다 더해서 방문 횟수인 N으로 나눠서 얻은 평균값이 된다. 여기서 $(S_t, A_t, S_{t+1})$ 은 sample experience가 된다.
- $\hat R^a_{s}$ 는 state s 에서 받은 reward 의 평균값이다. reward function 이 되는 셈이다.
아주 간단히 state 는 A,B 두가지 밖에 없고, discount factor 도 없고, sampling 할 수 있는 exerience 는 총 8 종류 밖에 없는 MDP를 고려해 보자.

에피소드 총 8개를 기반으로 각 에피소드를 진행해본 모델이 어떤 모델이었는지를 table lookup 방식으로 추정해보 결과이다.
A에서 next stage로 이동해서 reward 0은 딱 한번 있었으므로 이 구간의 probaility 는 100%가 된다.
B에서 next stage 로 이동해서 reward 1을 받은 케이스는 B 상황 총 8개 중 6개 였으므로 75%가 된다.
반대로 B에서 next stage 로 이동해서 reward 0 을 받은 케이스는 B 상황 총 8개 중 2개 였으므로 25%가 된다.
이런 식으로 모델 안의 transition probability 가 추정 되었다.
Model Planning
이제 방금 추정한 모델을 True label 이라고 생각하고 MDP를 구성 해보자.
Learning 하여 추정해 본 model M은 $M_\eta = <P_\eta, R_\eta>$ 이며 $\eta$가 붙은 것은 추정치라는 뜻이다.
우리는 이 추정치를 true label 이라고 생각하기로 했으므로 이 문제는 이제 $MDP <S,A,P_\eta,R_\eta>$ 꼴로 다시 쓸 수 있다. 즉, 아무것도 없는 무에서 추정치이기는 하지만 Model based 문제가 된 것이다.
Model based 문제가 되었다는 것은 이제 지금껏 살펴봐온 value iteration, policy iteration, Tree search 등의 방법을 통해 Planning을 하여 optimal 을 뽑아 낼 수 있다는 것을 의미한다.
하지만 우리는 여기서 기존에 배웠던 방식을 배제하고 조금 더 효율적인 planning 을 고려 해볼 수 있다.
이 기법은 Sample based planning이라고 하는데,
추정된 MDP 모델을 기반으로 샘플을 만들어 내고 그 샘플을 기반으로 결국에는 Model Free control 문제를 푸는 형태로 변환 하는 기법이다. 샘플은 시뮬레이션 된 experience 로 만들어 낸다.
Model을 완전히 아는 Model based learning 에서는 DP 기법을 활용하여 전혀 답에 가까이 갈 수 없는 action 도 모두 계산하여 비효율 적인 학습을 하는데, 이렇게 sample base로 Model Free learning을 하면 모든 s,a pair를 돌일한 확률로 고려 하는것이 아니라 더 자주 일어나는, 더 확률이 높은 state를 먼저 고려하여 Planning 을 하므로 더 효율적이라 할 수 있다.
상식적으로 고려해 봐도, 추정 된 모델에서 새로운 시뮬레이션 경험을 만들면 확률 P가 높은 pair 가 샘플링 될 확률이 높아 지게 되므로 더 효율적인 연산이 이루어 질 것이라는 것을 알 수 있다.
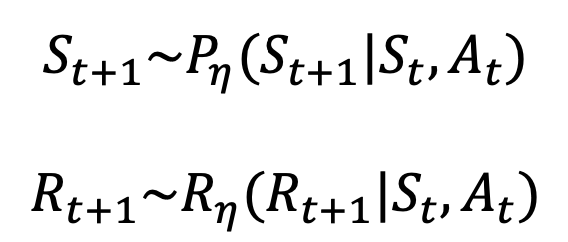
요약 하면, 추정된 모델을 기반으로 만든 또 다른 샘플들을 가지고 Model Free RL을 하여 Control 문제를 해결하는 식을 최적화 하는 것이다. 익히 배워왔듯이 이 Model Free RL을 위해서 우리는 MC control 이나 Sarsa, Q-learning등의 기법을 적용할 수 있다.
여기서 우리는 Experience 를 Real experience 와 Simulated experience 두가지로 나누어 생각해볼 수 있다.
Real Experience는 Model learning 단계에서 Model을 true label 로 만들 추정모델을 만드는 실제 경험이라고 할 수 있다. 즉, 우리가 알지 못하는 레알트루 MDP 를 통해서 일단 경험해보고 얻는 진짜 경험인 것이다.

Simulated Experience는 추정된 추정MDP 에서 샘플을 추출하여 시뮬레이션 한 경험이다.
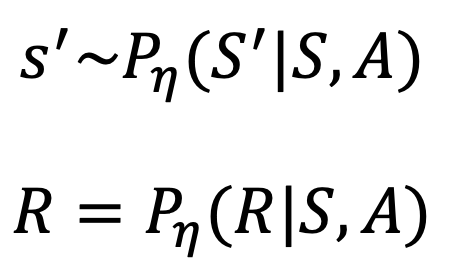
이 두가지 경험의 관점에서, 또 다시 아까의 그 AB example을 꺼내 보자.
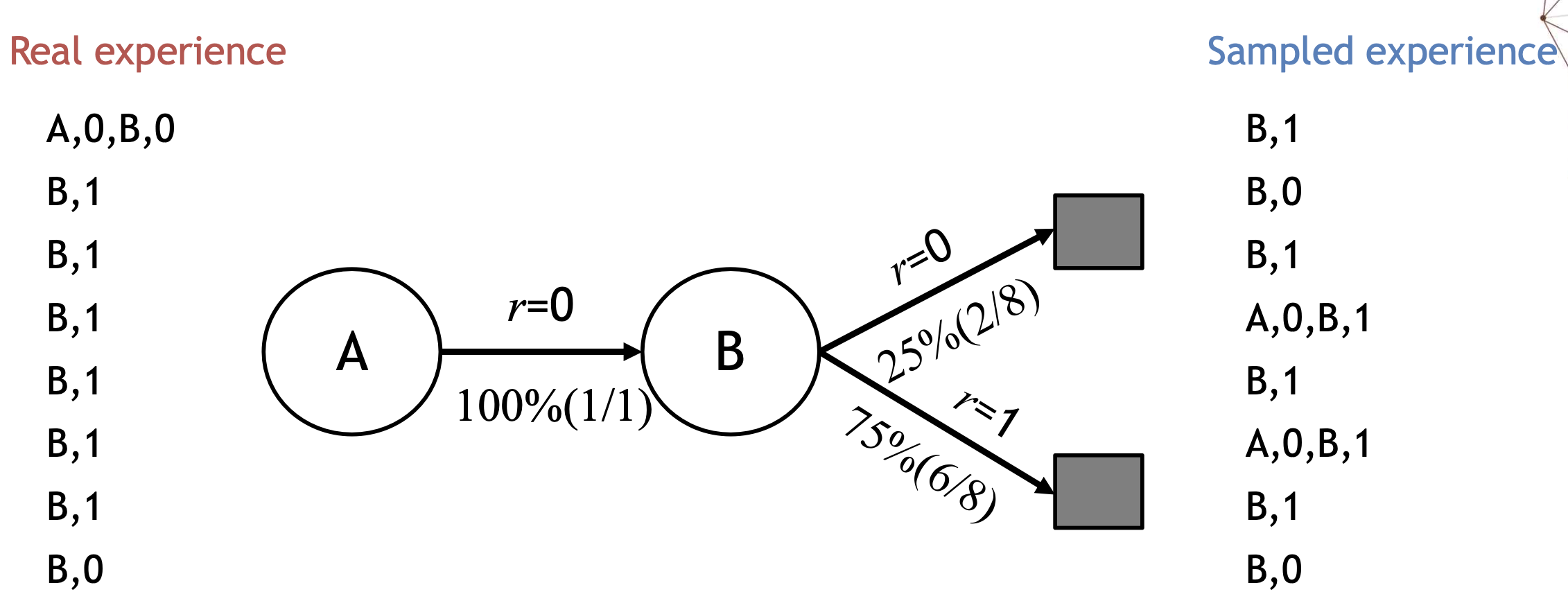
Sampled experience 에서 4번째 experience와 6번째 experience를 보자.
새로운 시뮬레이션을 계속 하다보면 새로운 샘플들이 만들어지므로 이것을 기반으로 더 좋은 control이 가능해지게 되는 것이다. 이렇게 sample 을 무한히 만들어 낼 수 있으므로 이 샘플을 가지고 Model Free 방식으로 Control 하는것이 핵심이라 할 수 있다.
꽤 긴 시퀀스를 따라 내려오다보니 바로 이해가 잘 안될 수 있는데 step별로 요약해보면 아래와 같다.
- [Step1] real experience 를 가지고 실제 에피소드를 진행하여 나온 결과를 가지고 먼저 학습
- [Step2] 학습된 estimated MDP에서 simulated experience를 샘플링하고 새로운 에피소드를 생성
- [Step3] 새롭게 다시 Planning
Dyna Architecture
이렇게 learning 과 planning 을 결합한 형태의 학습을 Dyna architecture 라고 한다.
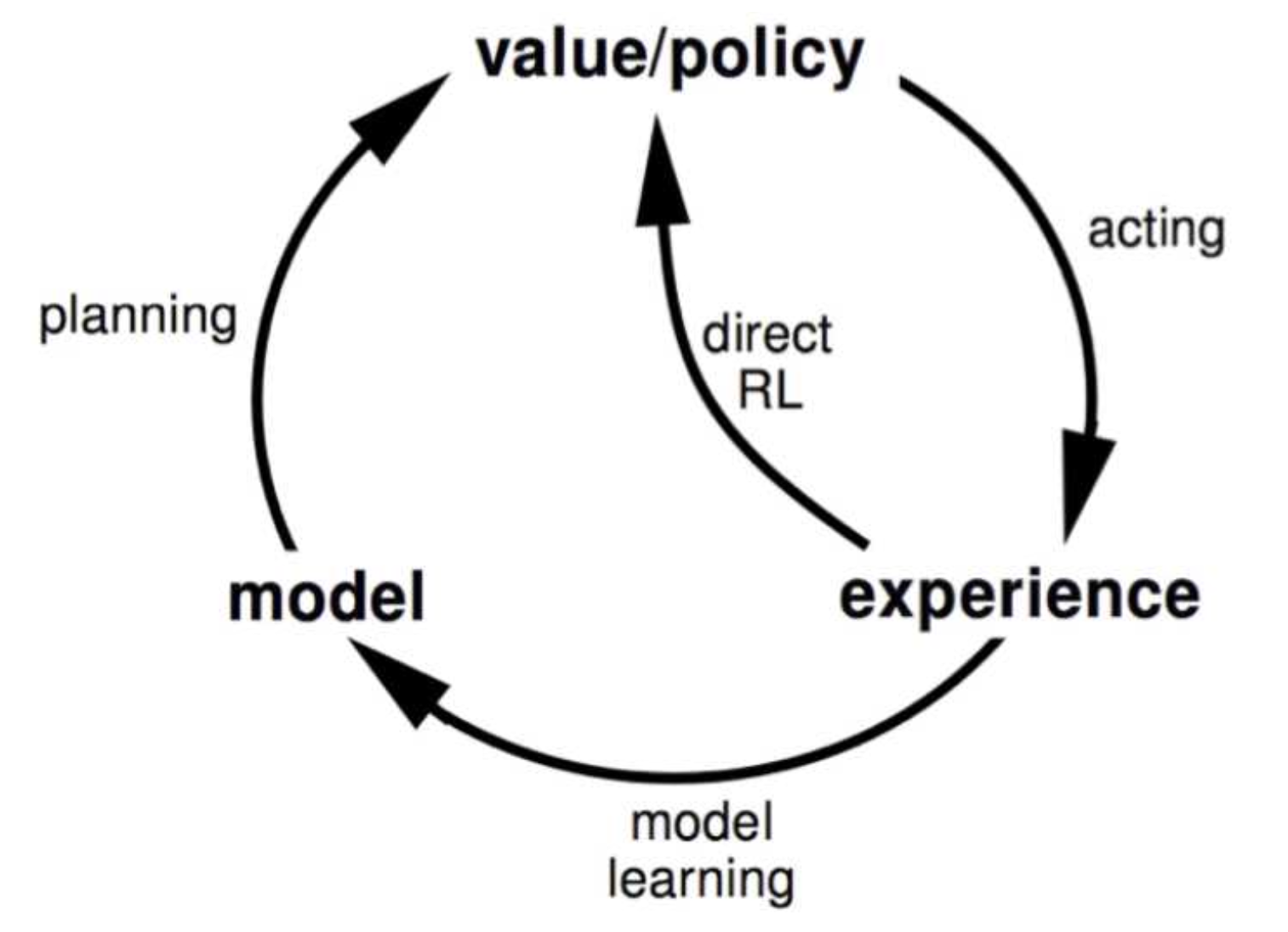
원래의 model based RL에서 실제 action 을 수행하여 얻은 experience를 가지고 바로 value/policy functio을 업데이트 하여 학습하는 과정이 추가 되었다.
이 Dyna Architecture를 설명하는 Dyna-Q 알고리즘의 pseudo code를 살펴 보자.

- nit : 초기 Q(s,a) pair 와 Model(s,a) 를 정의한다.
- a : 시작 state 를 정의 한다.
- b,c : action A를 $\epsilon$-Greedy 형태로 선택하고 수행 함으로서 실제 real experience를 얻고 실제 확률 값을 얻는다.
- d : Q러닝을 통해 Q 값을 계속 업데이트 해 나간다
- e : Model(s,a) 를 추정 된 값으로 업데이트 한다. enviroment 가 assume 된 결과 이다.
- f : 하위로 있는 로직은 모두 업데이트 된 추정 MDP를 가지고 simulation experience 를 계속 얻는 과정이다. 즉, 컴퓨터가 가상의 게임을 하는 단계라고 보면 된다.
이 과정을 통해 Real experience 와 simulated experience 를 결합 시켜서 한번의 과정으로 최종 해답 까지 찾아갈 수 있는 것이다.
마지막으로 Model based 와 Model Free 그리고 Dyna architecture학습방식을 요약하면 아래와 같이 정리 된다.

이번 정리는 아무것도 모르고 s,a pair에 대해 받는 r 만 확정적으로 알고 있는 environment에서 실제 action 을 수하는 real experience로 모델을 추정하여 Model based 로 만들고, 이 추정 MDP에서 시뮬레이션용 샘플을 만들어 낸 후 simulated experience로서 Control 하는 과정을 살펴 보았다.
이렇게 learning 과 planning이 결합 됨으로 인해 우리는 조금 더 간결하게 Model 을 바로 학습하여 문제를 해결 할 수 있게 되었다.
다음 정리에서는 이러한 시뮬레이션 기반의 여러 episode 진행 시 반드시 필요한 tree search 기법에 대해서 다뤄 볼 예정이다.
'Artificial Intelligence > Reinforcement Learning' 카테고리의 다른 글
| Exploration and Exploitation (2) | 2023.05.11 |
|---|---|
| 검색 - Search Technique (0) | 2022.06.13 |
| 추정 - Value Function Approximation (0) | 2022.06.06 |
| 모델프리 학습 - Model Free Learning - Control technique on Off-Policy (0) | 2022.06.01 |
| 모델프리 학습 - Model Free Learning - Control technique on On-Policy (0) | 2022.05.30 |




댓글